By Cody Baker

Every loan applicant signs a stack of legal documents. For a long time, we treated those documents like files. Here's what changed when we started treating them like code.
The Insight That Changed Everything
A document is completely defined by two things: the template and the data used to render it. The PDF is just the output of combining them. As long as those two pieces are stored, we can correctly reconstruct any document at any time.
That's the core idea behind Prime's document engine. Everything else follows from it: versioning, hydration, compliance auditability.
If you've ever worked in fintech, or any regulated field, you know the feeling that made us get here. Somewhere in your codebase, there's a dark corner where compliance documents get generated. A directory full of mismatched templates and strange conversions from "disbursement_amount" to "credit_provided_by_lender" that you pray are still accurate (since you're probably the first person to see this code in 6 months), convoluted rendering pipelines that have more exceptions and one-offs than happy paths. We had much the same.
As we were migrating to FastAPI, we had an opportunity. We were starting from the ground up in a new service, with a much better understanding of the requirements and a known good output to compare against.
What We Were Replacing
I was not at Prime when the original system was built, but I did see how it wore down as the scope of what it needed to do exploded. Multiple partners and multiple banks, each with their own requirements, plus state-specific regulations. The chain of if/else statements went from "that's manageable" to "I need to zoom out."
Each document type had its own generator class (FinanceAgreementGenerator, OfferSummaryAgreementGenerator, and so on), each with a dedicated DTO, an HTML renderer, and a PDF renderer. The service layer wired it all together with a long if/elif chain that manually fetched borrowers, lenders, partners, and loan terms for every document type.
Adding a new lender meant copying a generator class, creating a new DTO, and adding another branch. Adding a new state meant touching the chain again. It served us well for a year and a half, but the cracks started to show as we bolted on more and more and the changes became multiplicative instead of additive.
There was no one thing that finally made us rebuild. It was a building tension across a few pain points that got harder to ignore.
The biggest was version control. When legal changed a sentence in a document, we overwrote the template file. That meant we couldn't re-render a document that was signed under the previous version. For a compliance team that needs to pull up what a borrower actually signed six months ago, that's not great.
The second was regeneration. We didn't store the inputs that produced a document. There was even a comment in the code that said it plainly: "As we don't store html content in DB, we need to generate the html content every time." It wasn't wrong. It was just expensive, and fragile.
The migration to FastAPI gave us a clean exit. A fresh chance to take all these pain points and build something that actually works for where we are now.
What We Store
The practical consequence of "template plus data" is simple: that's what goes in the database.
{
"reference_id": "189eada4-...",
"document": "OfferSummary",
"template_name": "offer_summary_agreement_fee",
"template_version": "v20260107",
"template_data": { ... },
"signed_at": "2026-03-05T16:07:47Z"
}
The document field is just the class name (OfferSummary, LoanAgreement, ItemizationAgreement). It tells us how to reconstruct the object later. The template_data is everything that was computed at creation time. Together they're a complete recipe for regenerating the PDF without re-running any business logic.
One Document Engine to Generate Everything

We started with a TemplateCore base class that holds the versioned HTML template reference and the logic for rendering: PDF conversion, base64 encoding, and so on. Each specific document type subclasses it and handles its own construction logic.
Not all documents require advanced computations or personalized information. Take CreditPullConsent. Nothing is specific to the customer, partner, or bank. It still goes through the same engine with the same interface, but the template_data dictionary is empty. We call these static documents.
The earlier documents (OfferSummary, LoanAgreement) are dynamic documents, and that's where it gets interesting.
OfferSummary needs to know the loan product type, the state, the principal amount, the finance charge, and a handful of other values. Depending on whether the loan is fee-based or interest-based, the calculation logic is completely different. In the old system, that meant separate generator classes and separate DTOs. Now it's a single class with a match statement that routes to the right calculation:
match program_offer_type:
case "origination_fee":
# Fee deducted from disbursement
funding_amount = principal - finance_charge
total_payment = principal
case "origination_fee_no_interest":
# Fee added to repayment
funding_amount = principal
total_payment = principal + finance_charge
case "fixed_interest" | "daily_interest_accrual":
# Traditional interest-based
funding_amount = principal
total_payment = principal + finance_charge
The constructor handles the math, formats the currency, and stuffs everything into template_data. By the time it reaches TemplateCore, it's just a dict and a template reference. Same interface as the static documents.
The Hydration Pattern
This is the really neat part.
The constructor performs calculations and formatting when a document is first created. When reconstructing a historical document, we must not run those calculations again. Imagine recalculating a signed offer summary and getting today's date instead of the date the borrower signed it. The output would be wrong.
The solution is a small Python trick: we bypass __init__ entirely.
@classmethod
def hydrate(cls, data_dump: dict) -> OfferSummary:
# Manually create an instance without calling __init__
inst = cls.__new__(cls)
# Call the TemplateCore __init__ method
super(cls, inst).__init__(**data_dump)
return inst
cls.__new__(cls) gives us a blank instance of OfferSummary without running any of its calculation logic. Then we call TemplateCore.init directly, which sets up the template reference and data from what was already stored. The result is a fully functional document object. Render it to HTML, convert it to PDF, whatever you need. None of the original business logic ran again
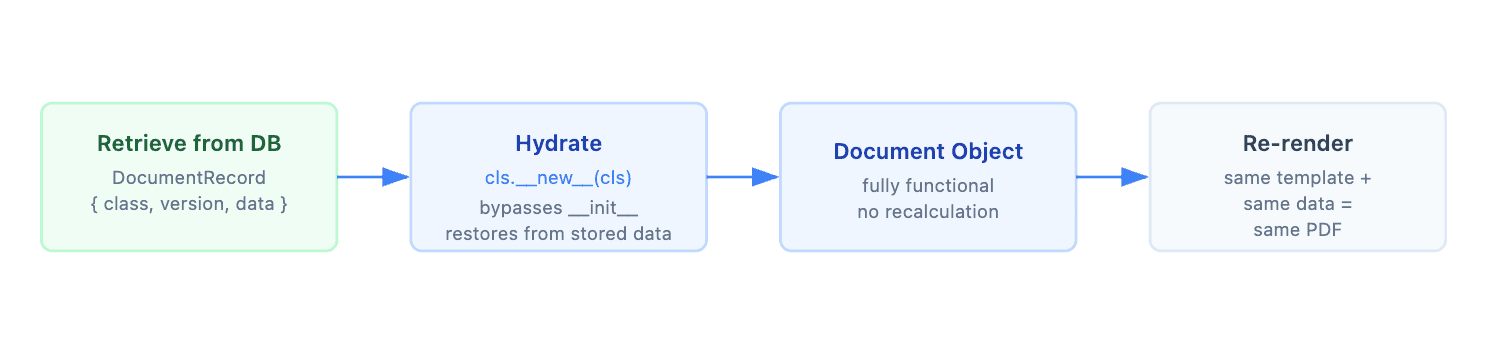
On the retrieval side, a simple dispatcher looks at the stored class name and routes to the correct hydrate method:
def hydrate_template(doc: DocumentRecord) -> TemplateCore:
match doc.document:
case "OfferSummary":
return OfferSummary.hydrate(doc.template_data, ...)
case "LoanAgreement":
return LoanAgreement.hydrate(doc.template_data, ...)
case "FinancingAgreement": # backwards compatibility
return LoanAgreement.hydrate(doc.template_data, ...)
# ... and so on
That FinancingAgreement case is one of my favorite details. We renamed the class from FinancingAgreement to LoanAgreement at some point, but documents signed under the old name are still in the database. One extra case in the match and they hydrate just fine. Real systems have warts like this, and the pattern handles it without any drama.
Now compliance can pull up any document ever signed and re-render it exactly as the borrower saw it, regardless of what the current template version looks like.
Versioning Without the Pain
Every template file follows a naming convention: {template_name}_{version}.html. When legal needs to update a document, we create a new date-stamped file. The old one stays right where it is, untouched.
Our templates directory tells the story pretty clearly:
loan_agreement_fee_v20250114.html
loan_agreement_fee_v20250212.html
loan_agreement_fee_v20260116.html
offer_summary_agreement_fee_v20250114.html
offer_summary_agreement_fee_v20260107.html
offer_summary_agreement_fee_CA_NY_v20250114.html
offer_summary_agreement_fee_CA_NY_v20260107.html
Three versions of the loan agreement coexisting. Two versions of the offer summary, plus state-specific variants for California and New York. Those states have their own disclosure requirements for fee-based products. In the old system, each of those would have been a separate generator class. Here it's a match on state code in the constructor that returns the right template name.
The version is also baked into the S3 key when we store the signed PDF: user/{id}/signed/{ref}{template_name}{version}.pdf. So even without the database, the filename alone tells you exactly what template and version produced it.
This is where the "documents as objects" insight really pays off. Adding a new field to template_data doesn't break old versions, because old templates simply don't reference it. Jinja2 with StrictUndefined catches it the other way. If a template expects a field that isn't in the data, it fails loudly at render time instead of silently producing a broken document. You find out in development, not in production.
What's Next
The regulatory landscape for small business lending is about to get more complex. Several states are preparing their own lending compliance laws, which means multi-state and multi-product verbiage across more surfaces than we currently handle. The architecture was built with this in mind, though it is not a perfect solution.
The business logic doesn't change, the storage doesn't change, the hydration doesn't change. But each variant needs its own HTML file. As we add more products and more states, that list is going to grow fast.
The direction we're heading is conditional rendering inside the templates themselves, combined with richer template data: instead of passing "finance_charge": "5.55", we pass "finance_charge": {"label": "Prepaid Finance Charge", "value": "5.55"}. The template renders whatever label it's given rather than having a state- or product-specific label hardcoded in the HTML. That's what turns a pile of near-identical files into a single template that adapts to its context.
The bigger move is extracting the document engine out of our core service into a standalone compliance package. The package owns the templates, the versioning, the term definitions, and the rendering. Engineering builds on top of it. Legal and compliance own what's inside it, with their own review controls and audit trail, separate from the core application workflow.
That boundary matters more than it might seem. Template changes going through a regulated path with proper ownership is a meaningfully different thing from a PR in a service that also handles loan origination. What changes is how we manage the templates upstream of that, and who's responsible for them. That's where we're headed.
The core contract doesn't change: given a template version and its input data, reproduce exactly what a borrower signed.
Want to learn more? Click here to schedule a demo.