By Michael Suzuki

The first version of our lending platform API looked correct. It exposed the right resources, followed familiar patterns, and did exactly what we asked it to do. The problem was that it was shaped around the wrong thing.
The API was designed around the data model. That meant the data model's constraints became the developer's constraints. To start a loan application, you first had to create a borrower. To add an owner to the business, you had to create a person and attach them to the borrower. To connect a bank account, you created a bank account record and associated it with the application. Each step reflected a foreign key relationship in the database, not a step in a lending workflow.
A developer trying to move a borrower through an application process had to think like a database administrator. The sequence was determined by referential integrity, not by what the workflow actually required. The sequence could be discovered and encoded in the frontend to avoid errors, but that created its own problem: the frontend now had to mirror the backend's stage order exactly. Any change to the backend sequence required a corresponding change to the frontend. The workflow lived in two places at once, and keeping them in sync was the integrator's responsibility.
The second problem was that encoding frontend state in the backend coupled every integrator to the platform's view of the user journey. The stage attribute was intended to capture application business state, but it absorbed frontend concerns as well — which step a borrower had completed, where they were in the flow. Because that state lived in the backend, every integrator had to implement it. There was no way to present the journey differently, defer a step, or reorder the experience without working around the backend's stage model. The frontend was not free to own the journey because the backend had already claimed it.
The third problem was that the platform had no concept of phases. A loan application has two fundamentally different modes. During authoring, information is being entered, corrected, and refined. During finalization, the application is under review and the data should be locked. The original API made no distinction between them. Every entity was mutable from creation onward. A correction during authoring would overwrite the existing record with no trace of what had changed or when. Once an application entered underwriting, nothing in the platform prevented further modification. The system treated in-progress input and finalized data identically, even though they have completely different requirements for correctness, traceability, and control.
Those three problems, a data-model-driven sequence, a backend that coupled integrators to the user journey, and no phase distinction, are what eventually drove us to redesign the API from the ground up.
What the Old API Actually Required
To understand why, it helps to look at what the original API actually imposed on developers. Before an application could be submitted for underwriting, a client had to create a borrower record, create person records and attach them to the borrower, create the application with the borrower attached, connect a bank account as a separate entity, and then advance the application through a sequence of explicit stage transitions, each guarded by the platform.
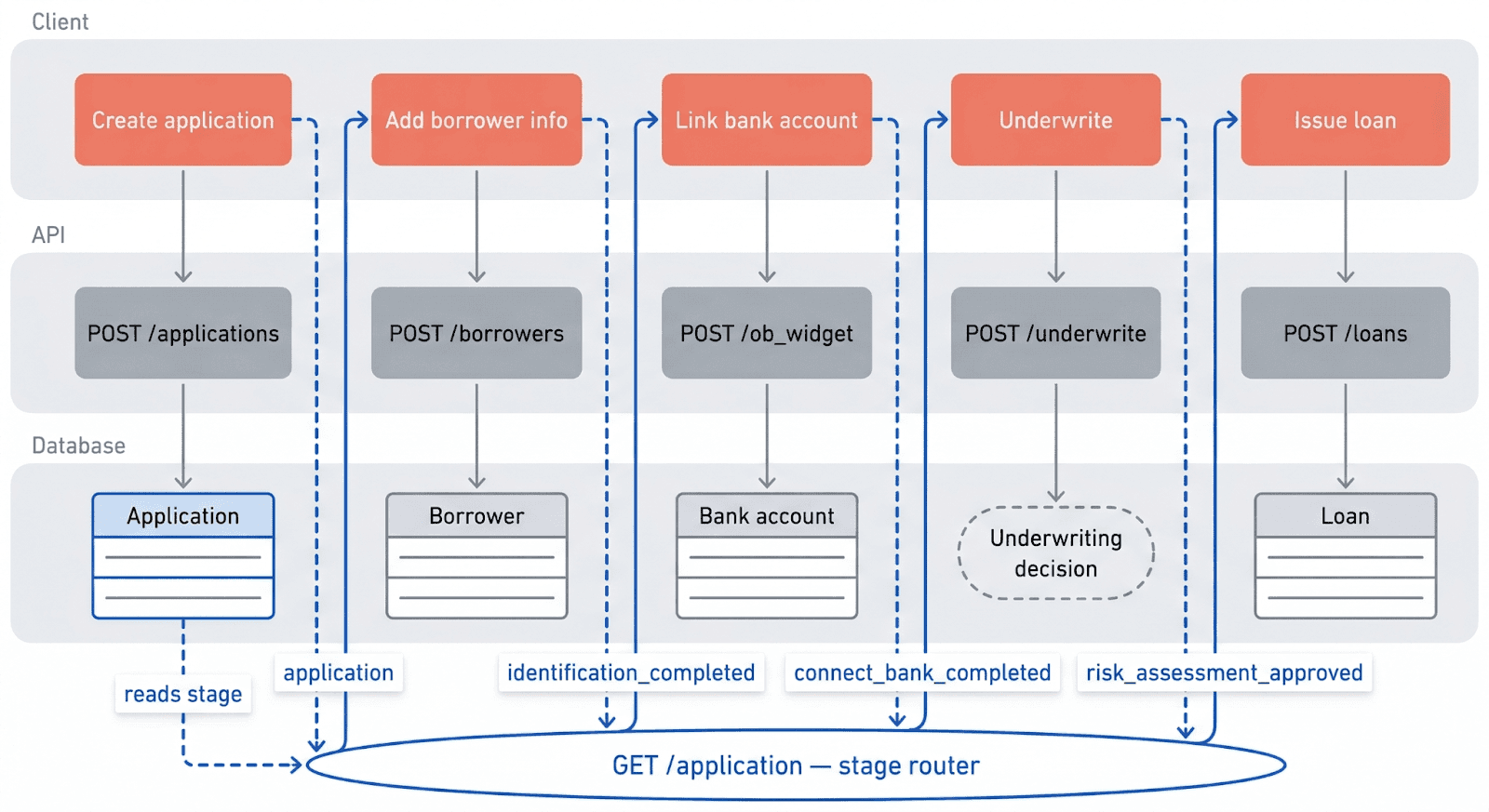
The sequence was not arbitrary. Each step followed from a database constraint. A borrower had to exist before an application could reference it. A person had to be attached to a borrower before they could be associated with the application. The platform enforced these dependencies, but it enforced them as data model constraints rather than as workflow rules. The result was an API that was technically consistent but conceptually wrong. Developers were not trying to satisfy foreign key relationships. They were trying to submit a loan application.
The stage model compounded the coupling. Because frontend state lived in the backend, the frontend had to implement the platform's stage sequence to function correctly. The two layers were not independent. A backend change to the stage order was also a frontend change, whether the frontend team intended it or not.
Authoring and Finalization Are Different Systems
A loan application has always had two distinct phases. The original API knew this implicitly. Stages and status fields did the work of expressing it, enforcing transitions between steps that represented gathering data and steps that represented acting on it. But the two phases were never named, never structurally separated, and never given different behavior in the data model. They existed as a concept embedded in the stage machine, not as a first-class design decision.
The redesign made the split explicit.
The first phase is authoring. A borrower is entering information, correcting it, and working through the required steps. They might revisit earlier fields, fix a mistake, or update their business details. The system needs to accommodate change. It needs to preserve history. And it needs to do so without treating every update as a permanent overwrite of a system-of-record entity.
The second phase is finalization. Once an application moves into underwriting and approval, the nature of the data changes entirely. It is no longer being written. It is being evaluated. Fields that were editable during authoring need to lock down. The entities that downstream systems depend on, borrowers, persons, bank accounts, loan terms, need to exist as stable, immutable records that servicing systems and compliance processes can rely on.
Those are not two steps in the same workflow. They are two different modes of the system, and they require two different data models.
The original API had one model for both. Entities were created eagerly at the start of the process and remained mutable throughout. The stage machine knew a transition had occurred. The data model did not. There was no structural boundary between the phase where data was being gathered and the phase where it needed to be fixed, only a set of stage guards expressing a distinction the underlying model never actually enforced.
What the Platform Should Own
Recognizing that the platform should own the workflow raises an immediate question: which parts of it?
There are two fundamentally different kinds of sequencing in a loan application. The first is business sequencing, the rules that come from the domain itself. You cannot underwrite an application without a bank connection. You cannot change an applicant's business information after a credit decision has been made. These rules are invariant. They are true regardless of how the process is presented, and they belong in the platform unconditionally.
The second is presentation sequencing, the order in which a borrower is guided through the process, how and when each step is surfaced, and what happens when a step is deferred or revisited. This varies across partners, products, and borrower contexts and is inherently a frontend concern.
The distinction is straightforward but important. The platform should enforce the rules that must be true and stay out of the order in which they are experienced.
Encoding presentation sequencing in the backend is precisely what created the coupling problem in the original API. It meant every integrator had to implement the platform's view of the user journey, and every change to that journey required coordinating two layers that should have been independent. Leaving business sequencing to clients creates the opposite problem: domain responsibility leaves the platform, and correctness becomes dependent on every integration getting it right. The platform's job is to own the first completely and stay out of the second entirely.
Centering the API on the Application
The redesigned API treats the application as the central object and exposes operations that reflect the business workflow rather than the underlying resource structure. Each operation advances the application through a meaningful transition. The platform validates that the conditions for that transition have been met and coordinates the services needed to carry it out.
The data model reflects the two-phase design directly. During the authoring phase, all data submitted by the client accumulates in a versioned pre-application record. Each update creates a new version. Nothing is overwritten. The full history of what was submitted, corrected, and changed is preserved automatically. This means that at any point during the authoring phase, the platform can reconstruct exactly how an application evolved, what was submitted first, what was corrected, and when each change occurred.
When the client is ready to originate, a single call commits the pre-application into the permanent record. At that point the platform creates all the entities that downstream systems depend on, borrower, persons, bank accounts, loan terms, in a single atomic operation. The mutable world becomes the immutable world. The application that was being authored becomes the loan that will be serviced.
This design also preserved compatibility with the downstream infrastructure that already existed. Origination, servicing, and data pipelines all continued to work against the same entity model they already knew. The two-phase approach did not require rebuilding the systems that consumed the final record. It only changed how that record was produced.
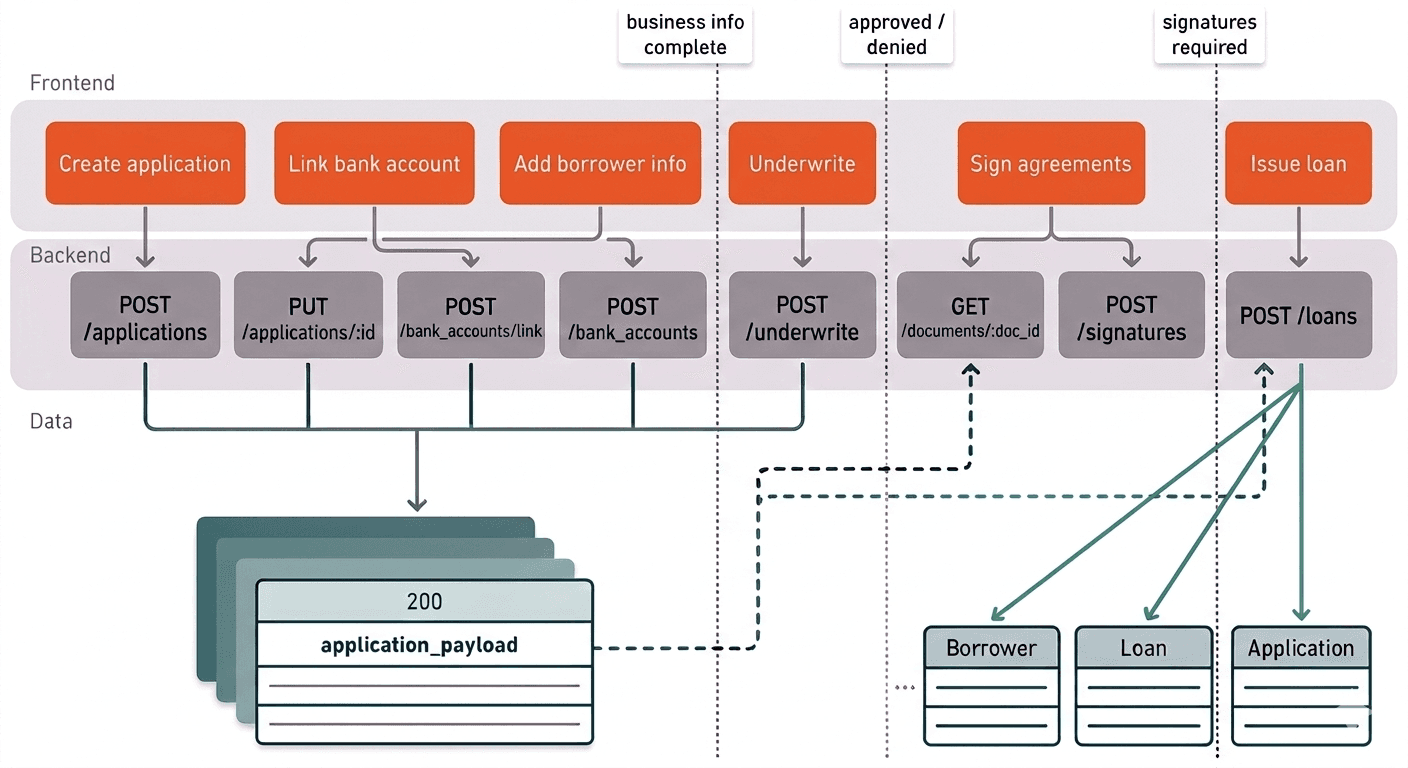
In this model the client interacts with a single object and calls operations that have meaning in the context of the workflow: add application data, get a link token, connect bank accounts, trigger underwriting, retrieve documents, sign, and create the loan. There are no borrower endpoints. There are no person endpoints. Those entities do not exist yet. They are created by the platform at origination, derived from the data the client submitted during the authoring phase.
Rather than prescribing the order in which those operations must be presented to the borrower, the platform returns a checklist alongside the application, a computed view of which conditions have been met and which have not. This gives frontend clients everything they need to guide a borrower through the process in whatever order makes sense for their product, without the platform needing to know or care about that order. The platform enforces the gates. The front-end owns the journey.
This distinction matters more as the platform serves more partners. A stage machine baked into the backend is a constraint that every integrator inherits. A gate-enforcement model with a checklist is a contract that any integrator can build on.
The Platform Should Own the Rules, Not the Journey
APIs are often designed around internal data models because those structures are the most natural starting point for the teams building them. The schema exists. The relationships are defined. It is straightforward to expose them directly as resources.
Over time that mapping breaks down. The data model reflects how the system stores things. The API needs to reflect what the system is being asked to do. Those are different problems, and when you conflate them the complexity lands on the developer, who now has to understand your storage model in order to accomplish something that has nothing to do with storage.
The shift we made was to treat the application as the unit of work and let the data model follow from that decision rather than drive it. During authoring the platform accumulates data in a form that supports change and preserves history. At origination it commits that data into a form that supports permanence and downstream consumption. The API reflects the workflow. The database reflects the outcome.
In workflow-driven systems the platform's responsibility is to enforce the rules that must be true and to model the transitions that matter. How those rules are presented, ordered, or experienced is a separate concern that belongs to the clients building on top of the platform.
The line is not between backend and frontend. It is between rules and journey.
The platform should own the first completely and stay out of the second.
Want to learn more? Click here to schedule a demo.