By Amine Azariz

When we started onboarding banking partners, reporting requirements arrived immediately: monthly disbursement files, reconciliation reports, state-level breakdowns. Across partners, auditors, and our servicing provider, we were looking at dozens of reports before we had built any reporting infrastructure at all.
The default answer is a data warehouse. We didn’t build one.
Instead, we used Postgres Foreign Data Wrapper (FDW) to turn the databases we already ran into a unified reporting surface—no ETL, no pipelines, no new infrastructure.
Where Engineering’s Job Ends
The key decision wasn’t technical. It was defining the boundary.
Engineering owns the system that produces data. Ops and accounting own the reports built from it.
They know what goes into partner files. They validate outputs. They handle reconciliation when something looks off. Engineering’s job is to make the underlying data accurate, accessible, and queryable—and stop there.
The cleaner version of this looks like:
A single reporting surface with all relevant data
Documented well enough that non-engineers can query it
Reports built and maintained without engineering tickets
Delivery handled by configuration, not code
If you get that boundary right, engineering’s involvement in reporting drops to near zero—and stays there.
That constraint shaped everything we built.
The Problem With Treating Reports as Application Code
The naive approach was straightforward: generate each report with application logic—whether that’s a Lambda per report, a job per partner, or a configurable reporting service.
It works—for a few reports.
But the problem isn’t Lambda itself. The problem is treating reporting as an engineering-owned system.
Once reporting logic lives in application code:
every new report becomes a deployment
every schema change becomes a maintenance task
every partner-specific variation becomes engineering work
ops cannot adapt reporting without filing tickets
At a small scale, that feels manageable. At reporting scale, it turns engineering into the long-term owner of operational reporting.
And it breaks down completely once you need to join across systems. Some of our reporting required combining internal lending data with an external servicing partner’s database. Without a shared query layer, that means duplication or a sync pipeline—which is exactly where you end up building the warehouse anyway.
We weren’t trying to reduce the number of functions.
We were trying to remove reporting from application code entirely.
All You Need Is Postgres
At that point, we assumed we needed a warehouse or an ETL pipeline. Then we looked more closely at what Postgres already provides.
Early-stage systems have a consistent failure mode: building infrastructure around assumptions that won’t hold. At that stage, every assumption is temporary. Building pipelines on top of temporary assumptions creates permanent maintenance.
Before adding a new system, it’s worth asking a simpler question:
What can the system we already run do?
In our case, the answer was enough.
Federated Queries: Foreign Tables, Local Queries
postgres_fdw allows one Postgres instance to query tables in another as if they were local.
Connect to a remote database, import its schema, and from that point forward:
You can
JOINacross databasesYou can aggregate across systems
You can query everything with standard SQL
The architecture is just a reporting database in the middle, connected to every source that matters.
No ETL. No sync jobs. No pipeline to maintain.
When a query runs, Postgres pushes as much work as possible to the source systems and returns the results. The data is always current.
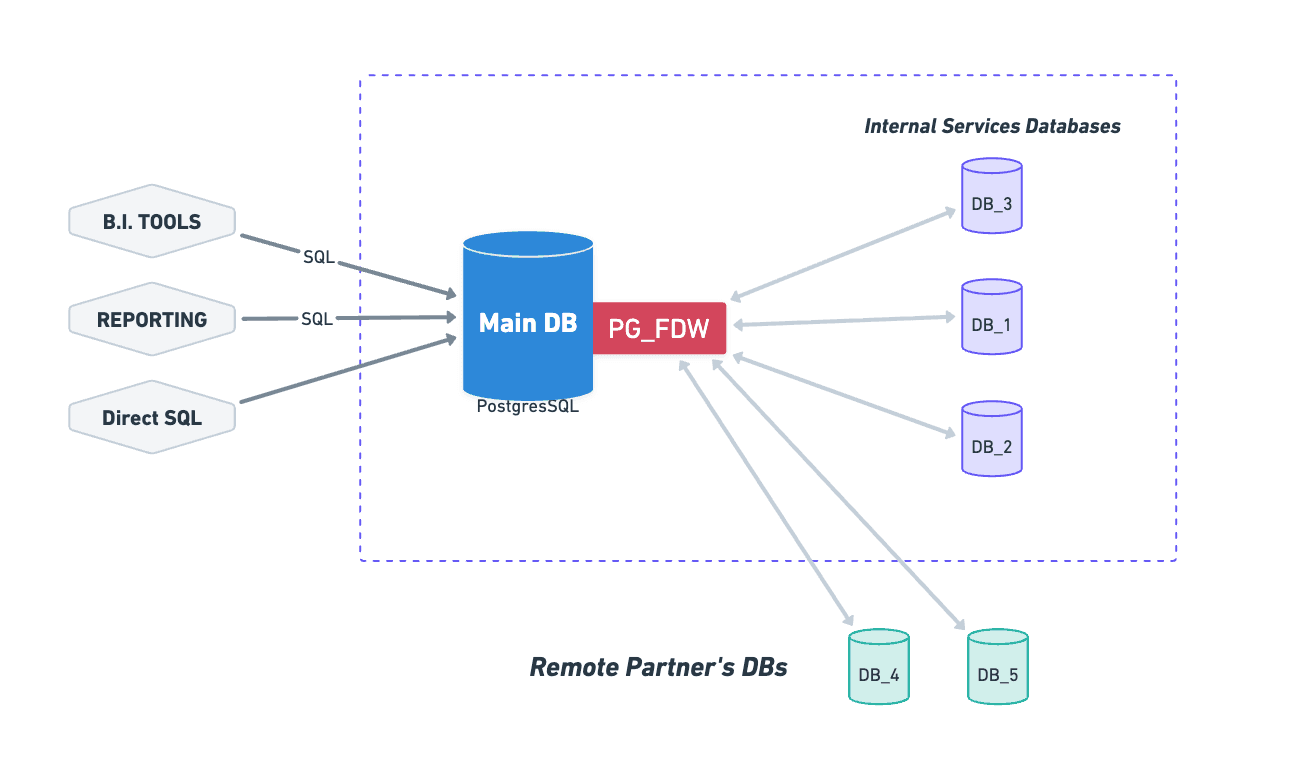
For the person writing the query, nothing changes. The cross-system complexity disappears.
What a Cross-Source Query Looks Like
A reconciliation report joining internal loan data with servicing data looks like this:
SELECT
l.id AS loan_id,
b.legal_name AS borrower_name,
l.capital_amount AS originated_amount,
l.status AS loan_status,
li.current_balance AS servicing_balance,
li.days_past_due AS days_past_due,
l.disbursement_at::date AS disbursement_date
FROM lending_fdw.loan l
JOIN lending_fdw.borrower b
ON b.id = l.borrower_id
LEFT JOIN servicing_fdw.line_items li
ON li.external_loan_id = l.id::text
ORDER BY l.disbursement_at;
Two different database hosts. One query. No data movement.
Without FDW, this requires duplication, synchronization, or a pipeline you now have to maintain. With FDW, it’s a join.
What We Built
Once configured, we had a single reporting database with tables from every relevant source:
Internal lending data
Servicing partner data
Payments data
We connected a BI tool directly to it. Ops and accounting could build reports themselves—either visually or with SQL.
No engineering tickets. No pipeline to build first.
For scheduled delivery, a workflow tool we already ran handled SFTP distribution. Engineering owns one thing in this chain: the FDW configuration. Everything downstream belongs to ops.
That was the goal.
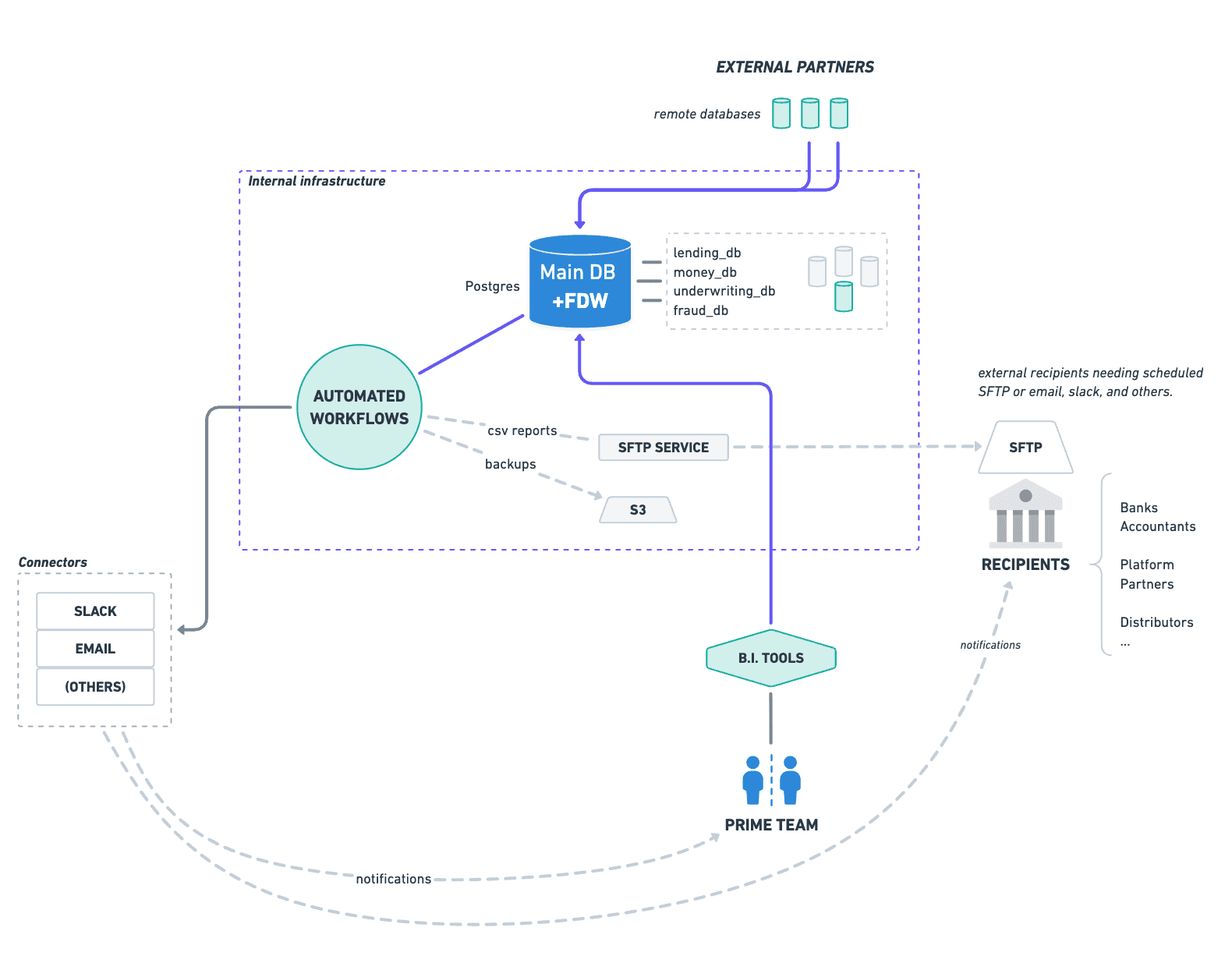
Adding a new data source takes minutes: define the connection, import the schema, and the tables are immediately available. If the schema changes, re-importing picks it up.
The same system now supports:
Compliance reporting
Partner reporting
Internal analytics
ML use cases
One setup, multiple uses.
Limitations
FDW is not a data warehouse, and it has edges.
Query pushdown. Filters and joins push down well on indexed columns. Complex expressions and cross-server joins don’t. When pushdown fails, performance degrades quickly.
No caching or pre-aggregation. Query latency depends on network round trips and source performance.
Connection counts. Each querying session opens connections to remote databases. At scale, this needs to be managed.
Schema isolation. Import each source into its own schema to avoid naming and type conflicts.
Monitoring. It’s easy to accidentally write a query that becomes a full remote scan. Logging and review matter.
For our workload—scheduled reports, batch jobs, and a small number of BI users—these constraints were acceptable. A high-concurrency analytics environment would need a different approach.
What You Don’t Get Without a Warehouse
A well-designed data warehouse does more than centralize data. It reshapes it.
Instead of exposing operational tables directly, it provides a curated schema built around reporting needs:
consistent naming across systems
normalized business concepts (loans, balances, payments)
abstractions over partner-specific differences
a stable interface that doesn’t change with the application
FDW does none of that.
It exposes the underlying systems as they are. Internal tables, external schemas, naming inconsistencies—all of it is visible to the query layer. Writing reports requires understanding how the product actually stores and relates data across systems.
That is a real tradeoff.
We accepted it because of where we are. Our reporting surface is used by a small number of people who are close to the system and can navigate that complexity. The cost of modeling and maintaining a curated reporting schema would have outweighed the benefit.
At a different stage, that trade flips.
When reporting consumers expand beyond the team that built the system—when consistency, abstraction, and stability matter more than immediacy—a warehouse stops being overhead and becomes necessary.
When FDW Is Not Enough
FDW isn’t better than a data warehouse. It’s earlier than one.
If it fits your stage, you’re likely still discovering:
what your reporting requirements actually are
which queries matter
how your schema will evolve
Building a warehouse before those stabilize means maintaining it through constant change.
FDW gives you a working system immediately, without committing to those assumptions.
When we eventually build a warehouse, we’ll do it with:
real query patterns
stable reporting requirements
a data model we understand
The Real Outcome
The biggest benefit wasn’t avoiding a warehouse.
It was removing engineering from the reporting loop.
We built a system where:
data is unified
reports are self-service
changes don’t require deployments
And we deferred a major architectural commitment until we had enough information to make it correctly.
Most teams don’t build warehouses too late. They build them too early.
We didn’t skip the warehouse.
We postponed it until we knew what it should be.
Want to learn more? Click here to schedule a demo.