By Michael Suzuki

Redesigning the API around the application workflow solved the problem for clients. But it surfaced a harder question internally: if the application was now the central object, why was it still stored as a dozen separate tables?
Moving an application through its workflow meant coordinating writes across borrower records, person records, business entities, bank accounts, and more. Each of those tables had its own validation logic and its own update semantics. Keeping them consistent as an application progressed wasn't technically impossible, but it required care that shouldn't have been necessary. The application was the unit that mattered. The storage model didn't reflect that.
Mutation made things worse. When a borrower record was updated, the previous values were gone. Knowing what had changed, and at what point in the workflow, required auditing infrastructure that had to be added separately and maintained independently. Without it, reconstructing how an application had evolved meant inference, not inspection.

Enforcing workflow boundaries across independent tables was its own challenge. Once an application moved past underwriting, certain fields, borrower information, business data, bank accounts, should stop being editable. In a model where those lived as separate mutable resources, enforcing that required coordination logic spread across multiple services rather than a single clear boundary.
The data model was working against the workflow, not with it. This is the second part of a two-part series. Part one covers the API redesign that preceded these changes and provides useful context for what follows.
Treating the Application as a Document
Once we started thinking about the application as a single object moving through a workflow rather than a relationship between independent entities, the storage model followed naturally. An application that is being authored and then finalized is not a set of rows in separate tables. It is a document. And documents are most naturally stored as documents.
Instead of storing each component as an independent resource, the redesigned system stores the application as a single JSON document within the application record. Borrower data, person records, business information, bank accounts, underwriting results, and agreements all live within that document rather than in their own tables.
Application
├─ borrower
├─ persons
├─ business
├─ bank_accounts
├─ underwriting
├─ agreements
└─ loan_terms
This gave us a single coherent object to reason about during the authoring phase, which aligned directly with how the workflow-oriented API presented the application to clients. The more significant question, however, was how updates to that document should be handled once we had it.
Versioning Instead of Mutation
The solution was to stop treating the application as a set of mutable rows and start treating it as an append-only record. In the redesigned system, the application document is never modified in place. Instead, each change produces a new version of the entire document, stored with an incrementing version number associated with the application ID. Each version is immutable. The most recent version represents the current state of the application, and every previous version remains intact.

Benefits of the Versioned Model
One of the goals we had going into the redesign was building audit capability directly into the data model rather than bolting it on afterward. The versioned document model accomplishes that automatically. Because every change to the application produces a new immutable version, the system maintains a complete record of how the application evolved without requiring any additional auditing infrastructure. There is nothing to configure and nothing to forget to enable.
The operational value of that history became apparent early. During initial test runs, being able to walk through the sequence of versions and see exactly how an application had progressed made it straightforward to understand what the system had done and why. Rather than reconstructing a sequence of events from current-state snapshots, engineers could inspect the actual history directly.
We did think carefully about the storage implications of keeping every version of every document. Sizing exercises suggested that even at millions of applications with tens of versions each, the data volume was not large enough to be a concern. And because versions are stored as independent records, there are straightforward paths to compaction or archival if that ever becomes necessary down the road.
Normalizing the Data After the Workflow
The versioned document model serves the system well while an application is moving through its workflow. At that stage the priority is managing workflow state, and having the entire application represented as a single coherent document makes that straightforward.
Once the application is complete, however, the system's needs change in a meaningful way. The application is no longer evolving, and the JSON document that worked well for workflow management is not the right structure for everything that comes next. Post-approval processes, servicing systems, and other downstream operations are built around normalized relational tables, and those systems need the data in that form to function.
So once an application reaches completion, the final version of the document is decomposed into its component parts and written into the normalized relational tables used by the rest of the platform. Borrowers, persons, bank accounts, loan terms, and other entities each move into their respective tables, where they can be queried and used in the ways those systems expect.
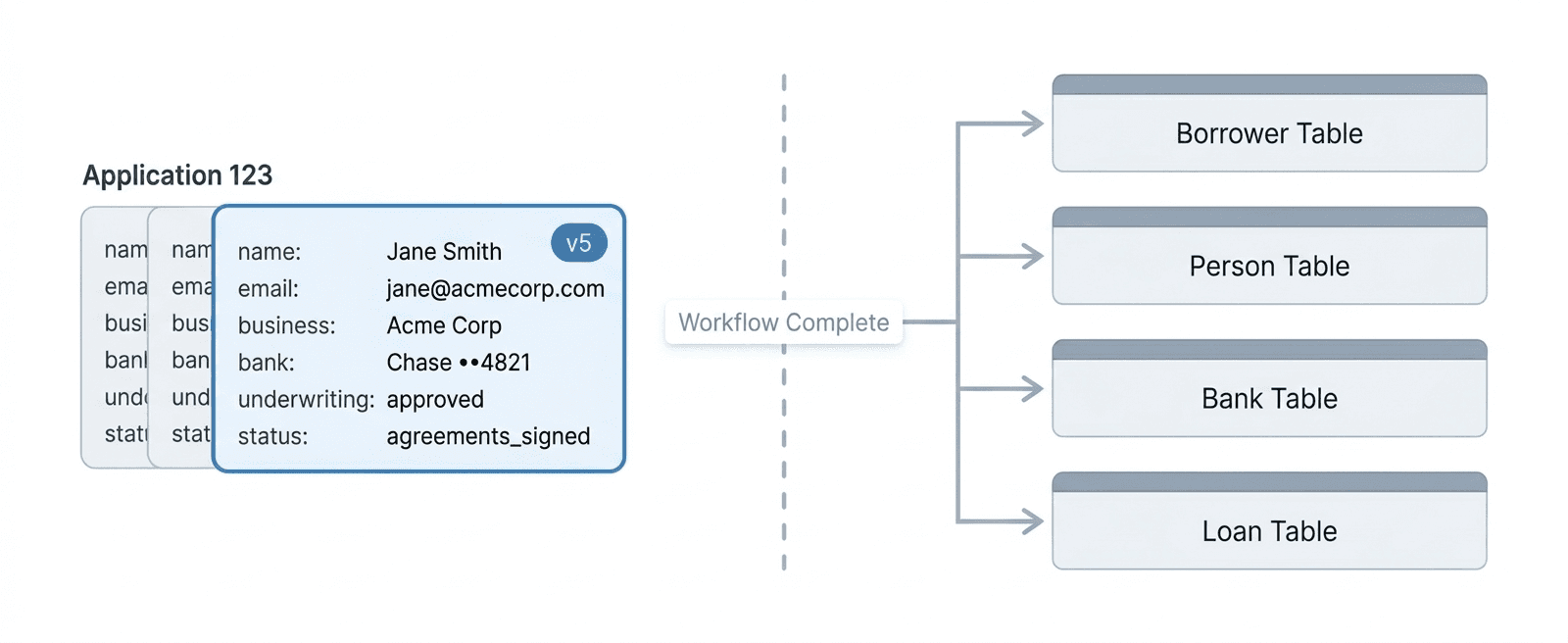
This step also marks a clean transition in the nature of the record itself. While the application was active it was a workflow under management. Once it is decomposed and written into the relational model, it becomes a finalized record. That boundary matters, and the decomposition step is where it gets enforced.
Architecture Summary
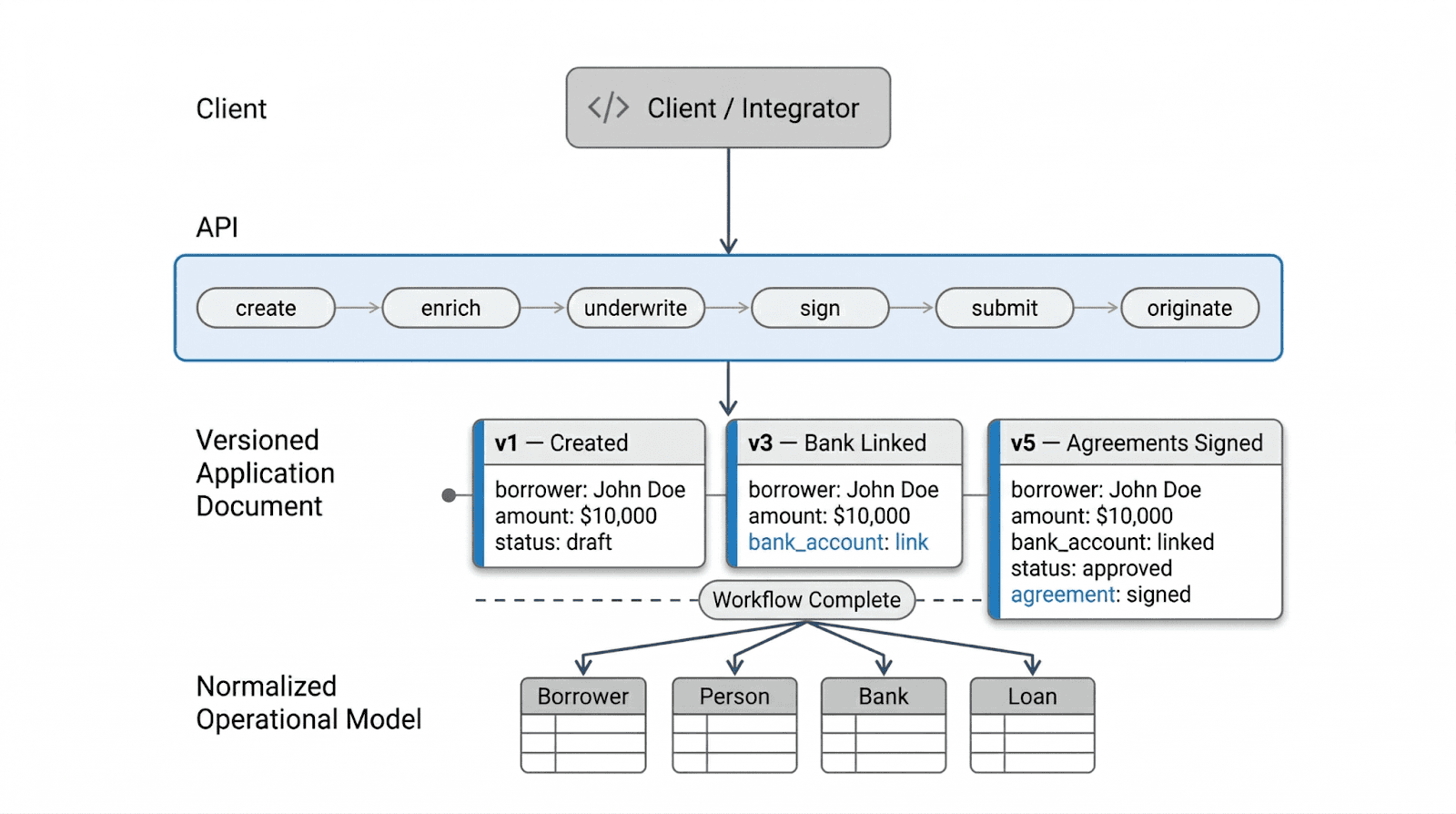
The sections above describe each phase of the workflow in isolation. The diagram below shows how they connect end to end, from the client integrating with the API through to the normalized operational model that downstream systems depend on.
This is the complete pattern. The API is centered on the workflow, the active authoring phase is represented as immutable versions of a single document, and the final state is decomposed into normalized tables once the workflow is done.
Aligning the Data Model With the Workflow
Many systems default to treating data as a collection of mutable resources because that approach maps naturally onto relational database design. For systems built around long-lived workflows, however, that default tends to introduce complexity that compounds over time, including scattered validation logic, lost history, and workflow boundaries that become increasingly difficult to enforce as the system grows.
The approach we landed on uses two different models for two different phases of the workflow, and the division turned out to be both architecturally sound and practically necessary. While an application is active, the versioned document model simplifies workflow coordination, preserves the full history of changes, and gives the system a single coherent object to reason about. Once the workflow completes, the document is decomposed into the normalized relational tables that the rest of the platform depends on. Post-approval processes, servicing systems, and downstream operations all rely on those structures being in place, so the decomposition step was never just about data hygiene. It was also the point at which the application formally stopped being a workflow and became a finalized financial record.
What we found was that data models do not need to be uniform across the full span of a system like this. Workflow management and long-term record keeping are genuinely different problems with different requirements, and trying to solve both with the same model tends to mean solving neither one particularly well. Separating them, and being deliberate about when the transition between them happens, was what allowed the system to stay coherent as it grew.
Want to learn more? Click here to schedule a demo.